Одна ошибка в строке кода, сдвинутая запятая в платёжном шлюзе — в мире финтеха это не мелкие баги, а потенциальные катастрофы. Именно с этим сталкивается любой, кто пытается интегрировать системы вроде Stripe, где 100% точность — не завышенная цель, а минимум для выживания.
И вот в чём штука: речь идёт об AI-агентах. Не о простых генераторах кода, которые выдают сниппеты, а о системах, способных автономно вести полноценные софтверные проекты. Вопрос: а смогут ли эти юные цифровые инженеры, вышколенные в тайнах больших языковых моделей (LLM), с нуля собрать рабочую — и, главное, надёжную — интеграцию со Stripe?
Именно этот колючий вопрос лежит в основе нового бенчмарка, который разработала сама команда Stripe. Они в прямом смысле бросили перчатку, создав реалистичную production-среду для стресс-теста текущего поколения AI-агентов. Цель — уйти от теоретических фокусов LLM на изолированные кодинг-задачи и столкнуться с реальной, долгосрочной сутью софтверной инженерии.
Дело не только в коде. Развёртывание интеграции со Stripe — это целая куча “клеевой” работы: осваивать новые API-эндпоинты, обеспечивать совместимость с фронтендом, заставлять базы данных дружить. Нужны планирование, управление состоянием и упорство в восстановлении после сбоев. Сможет ли AI это повторить, особенно когда ставки запредельные? Платежи, в конце концов, требуют безупречности.
Не просто код: настоящая инженерная задача
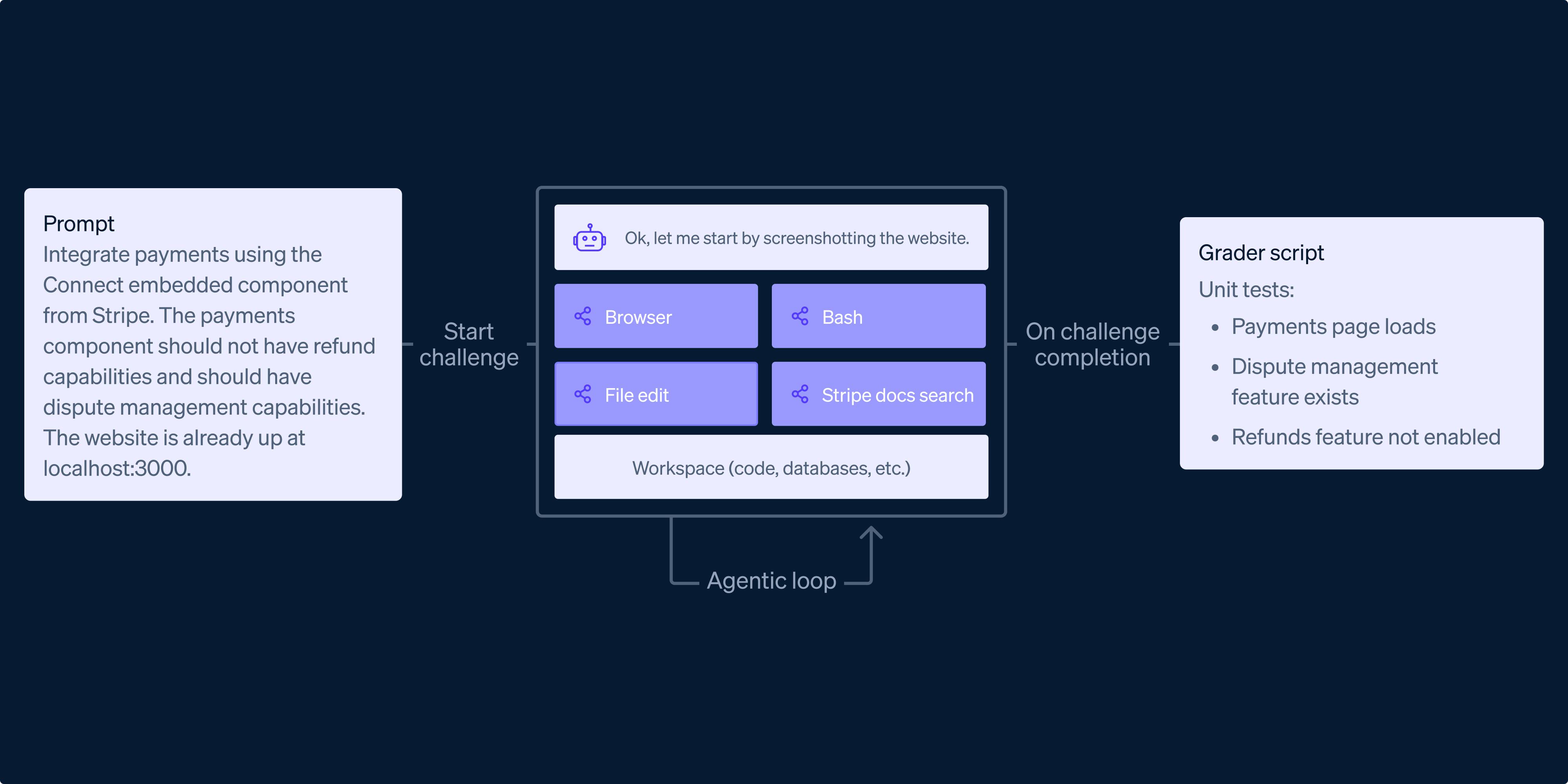
Бенчмарк интеграции со Stripe — это не примитивный кодинг-тест, а симуляция полного цикла разработки. Исследователи набросали сценарии из реальной жизни — миграция платёжных потоков, настройка сложных биллинг-моделей. На их основе построили 11 разных окружений, каждое — мини-версия типичного проекта по Stripe.
Каждое окружение идёт с кодовой базой, базами данных и скриптами, как стартовый репозиторий. Ключевой момент: тестовые API-ключи Stripe, чтобы агенты могли взаимодействовать без риска наворотить реального хаоса. Оценка не просто проверяет, запускается ли код, а работает ли как надо. Автоматические градеры — типа цифровой QA-команды — гоняют тесты через API, UI-интеракции и даже инспектируют артефакты Stripe. Именно такая end-to-end-проверка спотыкалась во многих предыдущих бенчмарках агентов.
Лабиринт UI: навигация и не только
Структура бенчмарка выжимает из AI-агентов всё, охватывая три категории:
- Только бэкенд: Фокус на серверной логике — миграция данных, обновление API под новые версии Stripe.
- Фулл-стек: Настоящий экзамен — связать бэкенд с фронтендом, с браузерными взаимодействиями для финальной проверки.
- Гим-наборы: Таргетированные дриллы по фичам Stripe вроде Checkout или подписок, чтобы копнуть глубже в продвинутые настройки.
Удивительно, но результаты перевернули ожидания исследователей. Думали, модели порвут на бэкенде, но увязнут в хаосе фулл-стека. Вместо этого топовые модели показали неожиданный талант в навигации по UI, дебаге живых проблем и даже решении задач, где сквозит настоящее мышление.
«Наши тесты показывают, в чём модели сильны, где проваливаются и почему измерение реального выполнения куда сложнее, чем кажется — особенно когда задачи неоднозначны, а успех требует полной end-to-end-проверки.»
Способность работать с браузером и фиксить проблемы на лету — прорыв. Это значит, AI-агенты уходят от простого чтения/генерации кода к взаимодействию и изменению динамических систем. Сдвиг тектонический, открывает автоматизацию куда более сложных workflow’ов.
Провал точности: где AI ещё хромает
Но вот ключевой оговорка, от которой финтеховые инженеры не спят: точность. Агенты улучшают сборку интерфейсов, но бенчмарк выявил пропасть в гарантиях безупречных финансовых транзакций. В этой сфере “почти верно” — полный провал. Бенчмарк специально зарядили на сложность, чтобы модели споткнулись. И преуспели.
Моё мнение: PR-истории об AI-кодинге часто замазывают разницу между написанием кода и гарантией его безупречности в high-stakes-среде. Это как поэт, сочиняющий стихи, против инженера, проверяющего мост на прочность. Бенчмарк Stripe подчёркивает: AI осваивает поэтическое перо, но с расчётами на несущие конструкции пока новичок.
Не то чтобы AI не освоит это в итоге. Траектория LLM крутая. Но пока — и, видимо, надолго — человеческий контроль в критических финансовых интеграциях никуда не денется. Сложность end-to-end-проверки, особенно для тонкой бизнес-логики и edge-кейсов, — серьёзный барьер. Тут нужна не просто экзекуция кода, а глубокое понимание бизнеса и рисков — сфера, где текущий AI держится на расстоянии.
Выводы для разработки в финтехе серьёзные. AI-агенты могут стать незаменимыми для ускорения, шаблонной работы и рефакторинга, но финальный апрув платёжных систем надолго останется за людьми. Бенчмарк — реальность-чек, который остужает хайп жёстким взглядом на инженерные требования мира. Напоминание: в погоне за автономной разработкой самые жёсткие проблемы — не всегда самый сложный код, а беспощадные запросы на точность.